动态链接
动态链接:程序内部的“共享单车”
程序的链接,是把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件。这个链接的方式,让我们在写代码的时候做到了“复用”。同样的功能代码只要写一次,然后提供给不同的程序进行链接就行了。
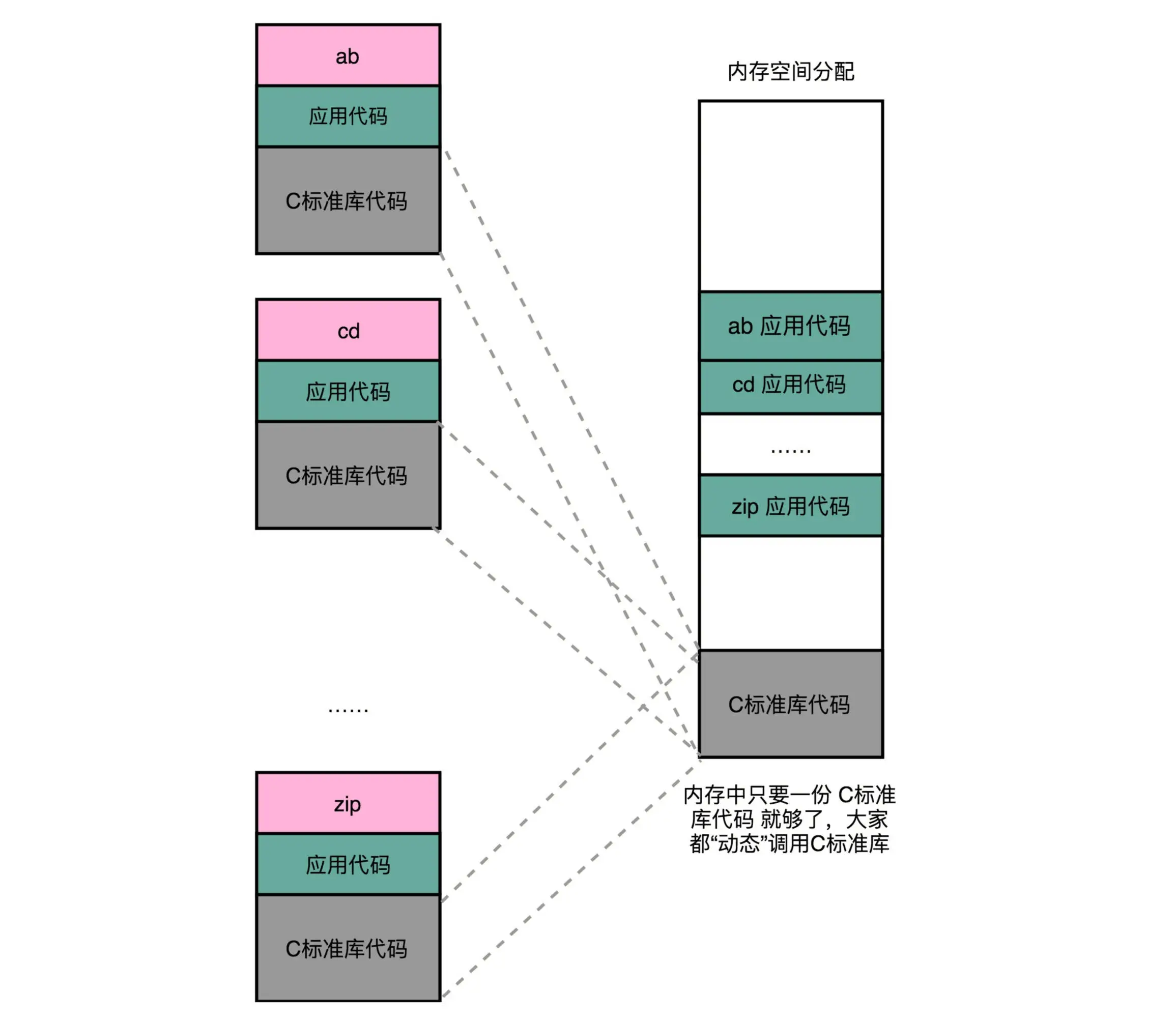
这么说来,“链接”其实有点儿像我们日常生活中的标准化、模块化生产。但是,如果我们有很多个程序都要通过装载器装载到内存里面,那里面链接好的同样的功能代码,也都需要再装载一遍,再占一遍内存空间。岂不是显得很冗余?
链接可以分动、静,共享运行省内存
如果我们能够让同样功能的代码,在不同的程序里面,不需要各占一份内存空间,那该有多好啊!就好比,现在马路上的共享单车,我们并不需要给每个人都造一辆自行车,只要马路上有这些单车,谁需要的时候,直接通过手机扫码,都可以解锁骑行。
这个思路引入一个新的链接方法,叫作动态链接(Dynamic Link)。相应地,我们之前说的合并代码段的方法,就是静态链接(Static Link)。
在DL中,我们想要的链接不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库。这个共享库的代码会被很多个程序的指令调用到。win系统下,这些共享库文件就是 .dll文件,也就是Dynamic-Link Libary(DLL,动态链接库)。在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库)。
地址无关很重要,相对地址解烦恼
想要在程序运行时共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。也就是,编译出来的共享库中的指令代码,是地址无关的(Position-Independent Code)。换句话说就是,这段代码,无论加载在哪个内存地址,都能够正常执行。
对于所有动态链接共享库的程序来说,虽然共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的的。
我们要怎么样才能做到,动态共享库编译出来的代码指令,都是地址无关码呢?
需需要使用相对地址(Relative Address)就好了。各种指令中使用到的内存地址,给出的不是一个绝对的地址空间,而是一个相对于当前指令偏移量的内存地址。因为共享库是放在一段连续的虚拟内存地址中的,无论装载到哪一段地址,不同指令之间的相对地址都是不变的。
PLT 和 GOT,动态链接的解决方案
我们还是拿出一小段代码来看一看。
首先,lib.h 定义了动态链接库的一个函数 show_me_the_money。
1 | // lib.h |
lib.c 包含了 lib.h 的实际实现。
1 |
|
然后,show_me_poor.c 调用了 lib 里面的函数。
1 |
|
最后,我们把 lib.c 编译成了一个动态链接库,也就是 .so 文件。
1 |
|
在编译的过程中,我们指定了一个 -fPIC 的参数。这个参数其实就是 Position Independent Code 的意思,也就是我们要把这个编译成一个地址无关代码。
然后,我们再通过 gcc 编译 show_me_poor 动态链接了 lib.so 的可执行文件。在这些操作都完成了之后,我们把 show_me_poor 这个文件通过 objdump 出来看一下。
1 | $ objdump -d -M intel -S show_me_poor |
1 |
|
在 main 函数调用 show_me_the_money 的函数的时候,对应的代码是这样的:
1 | call 400550 <show_me_the_money@plt> |
后面有一个 @plt 的关键字,代表了我们需要从 PLT,也就是程序链接表(Procedure Link Table)里面找要调用的函数。对应的地址呢,则是 400550 这个地址。
当我们把目光挪到上面的 400550 这个地址,你又会看到里面进行了一次跳转,这个跳转指定的跳转地址,你可以在后面的注释里面可以看到,GLOBAL_OFFSET_TABLE+0x18。这里的 GLOBAL_OFFSET_TABLE,就是我接下来要说的全局偏移表。
1 |
|
在动态链接对应的共享库,我们在共享库的 data section 里面,保存了一张全局偏移表(GOT,Global Offset Table)。虽然共享库的代码部分的物理内存是共享的,但是数据部分是各个动态链接它的应用程序里面各加载一份的。需要引用共享库外部的地址的指令,都会查询GOT ,来 找到当前运行程序的虚拟内存里的对应位置。而 GOT 表里的数据,则是我们加载一个个共享库的时候写进去的。
不同的进程,调用同样的 lib.so,各自 GOT 里面指向最终加载的动态链接库里面的虚拟内存地址是不同的。
这样,虽然不同的程序调用的同样的动态库,各自的内存地址是独立的,调用的又都是同一个动态库, 但是不需要去修改动态库里的代码所使用的地址,而是各自程序各自维护好自己的 GOT ,能够找到对应的动态库就行
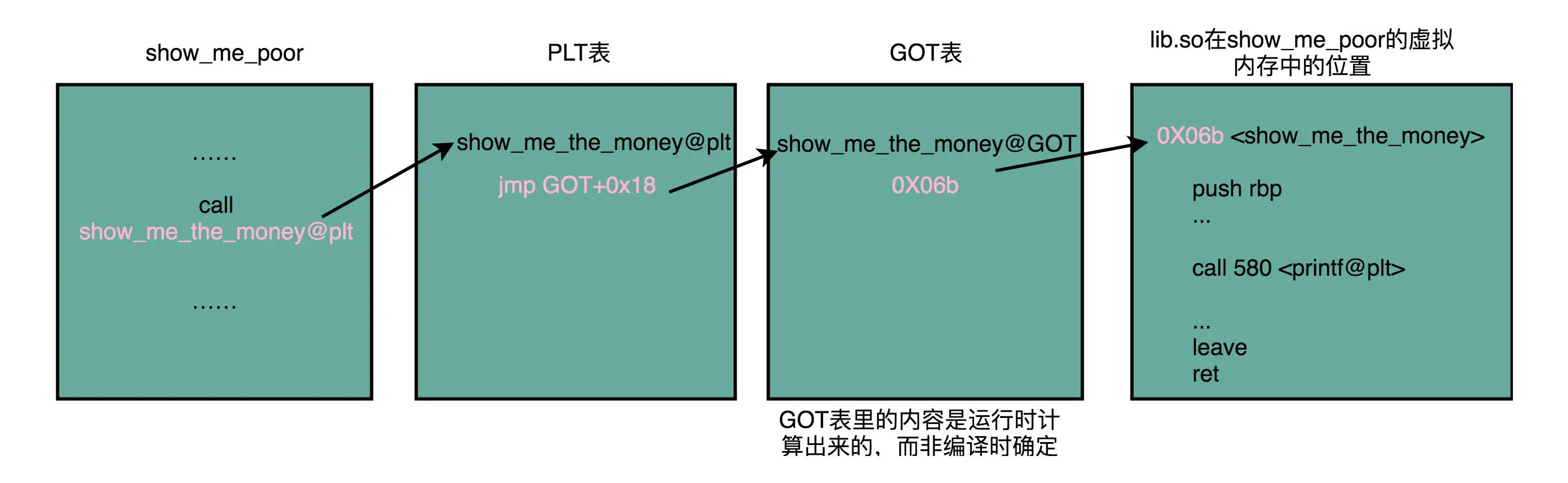
GOT 表位于共享库自己的数据段里,GOT 表在内存里和对应的代码段位置之间的偏移量始终是确定的。
这样,我们的共享库就是地址无关的代码,对应的各个程序只需要在物理内存里面加载同一份代码。而我们又要通过各个可执行程序在加载时,生成各个不同的 GOT 表,来找到它需要调用到的外部变量和函数的地址。
这是一个典型的、不修改代码,而是通过修改“地址数据”来进行关联的办法。它有点像我们在 C 语言里面用函数指针来调用对应的函数,并不是通过预先已经确定好的函数名称来调用,而是利用当时它在内存里的动态地址来调用。
总结延伸:
利用动态链接把我们的内存利用到了极致。同样功能的代码生成的共享库,我们只要在内存里面保留一份就好了。这样,我们不仅能够做到代码在开发阶段的复用,也能做到代码在运行阶段的复用。
实际上,在进行 Linux 下的程序开发的时候,我们一直会用到各种各样的动态链接库。C 语言的标准库就在 1MB 以上。我们撰写任何一个程序可能都需要用到这个库,常见的 Linux 服务器里,/usr/bin 下面就有上千个可执行文件。如果每一个都把标准库静态链接进来的,几 GB 乃至几十 GB 的磁盘空间一下子就用出去了。如果我们服务端的多进程应用要开上千个进程,几 GB 的内存空间也会一下子就用出去了。这个问题在过去计算机的内存较少的时候更加显著。
(内存中的共享库)